It’s november, and I’ve decided this month that I’m going to do 30 projects in 30 days. It’s an all-month hack-a-thon!
This is November 30th, so this will be the last project.
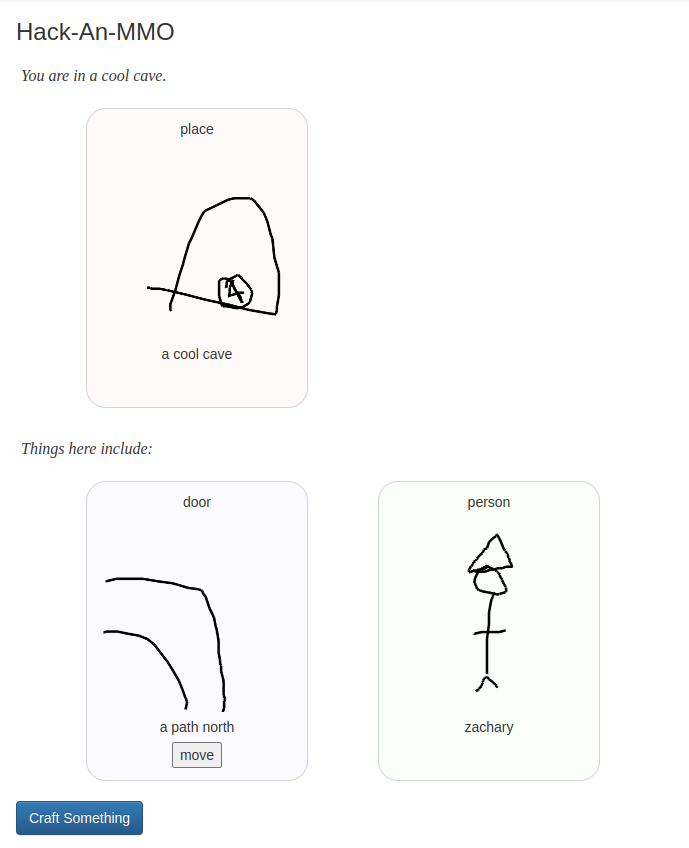
Today’s project is Hack-An-MMO (demo, source). It’s a small collaborative art RPG. You can draw people, places, and things to populate the tiny world. Have fun!
It’s november, and I’ve decided this month that I’m going to do 30 projects in 30 days. It’s an all-month hack-a-thon!
Today’s project is Hack-A-Farm (demo, source). It’s a simple tile-based RPG. You can walk around as a chicken, admire your house, and plant and harvest two types of crops.
My main goal with this project was to work with spritesheets or animation before, which I had never done. Showing off the individual tiles is deliberate. Also, the game should respond well to smaller and larger screens, I hope.
I had a good time with this one, and I’m happy with how much I got done in a day. I originally planned to do more fluid walking (it was called Hack-A-Walk), but it was more fun to add crops instead.
I re-used some of the logic from Hack-A-Minigame and Hack-A-Snake. I’ve been finding d3 to be mildly useful, if a little annoying.
It’s november, and I’ve decided this month that I’m going to do 30 projects in 30 days. It’s an all-month hack-a-thon!
Today’s project is Hack-A-Minigame (demo, source). It’s the classic Snake, but the twist is you can only save and load the game. Rather than controlling the snake, it moves at random under AI control. You have to repeatedly save and load to make progress.
Credit to Jeff Lait’s “Save Scummer” 7-day roguelike for inspiration. Although actually, this whole minigame is mostly for a future project!
It’s november, and I’ve decided this month that I’m going to do 30 projects in 30 days. It’s an all-month hack-a-thon!
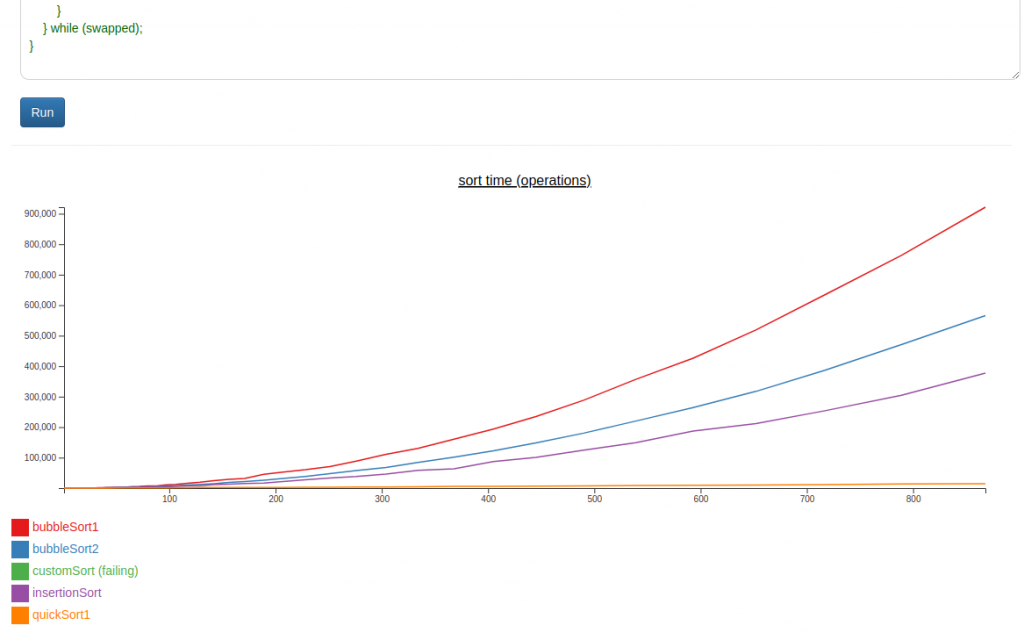
Today’s project was Hack-An-Experiment (demo, source). It’s designed to present the basics of experimental algorithmics, while also getting me acquainted with d3.
I have to say, I keep seeing d3 sold as a “graphing” library. And it’s definitely not. Maybe you could write one on top of it.
Thursday’s project was Hack-A-Clock (demo, source). It is a decimal time clock, displaying the time in revolutionary french time (minus their weird calendar).
https://tilde.za3k.com/hackaday/clock/
This is another “phone it in” project but I think it would have been okay with more accompanying explanation and better styling.
It’s november, and I’ve decided this month that I’m going to do 30 projects in 30 days. It’s an all-month hack-a-thon!
Today’s project is Hack-A-Hell (demo, source). It’s a bullet hell game combined with a music visualizer.
I’m happy with this one, although it took way too long given yesterday’s project! I keep thinking I’ll be able to modify or re-use things quickly, and it’s not true.
P.S. Taking the next day or two off for thanksgiving
It’s november, and I’ve decided this month that I’m going to do 30 projects in 30 days. It’s an all-month hack-a-thon!
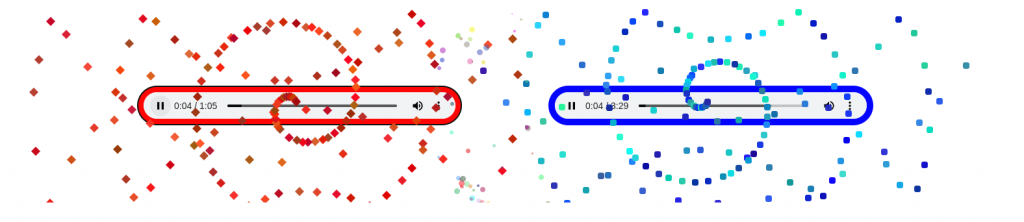
Yesterday’s project was Hack-A-Battle (demo, source). It’s two dueling music visualizers (sound warning!). Red vs blue. As each hits the other with bullets, they lose heath. As a band takes damage, it gets dimmer and quieter. Eventually one band will win out and be the only one playing.
I thought this was a cool idea, but I’m not really happy with the implementation
It’s a little laggy, especially when explosions happen.
It’s probably a little too fast of a battle.
I wanted to the things coming out to actually be linked to a music visualizer, which I almost had time to do.
It would have been better if the “bands” took turns playing instead of both going at once, for the poor listener.
It requires a fairly big display, and beefy computer/phone. It doesn’t work well on a small screen at all.
I wasn’t super pleased with the code. It was so-so
I wanted you to be able to upload your own songs and duel a friend