Today I wrote a simple raytracer. A raytracer is a very simple way to draw excellent graphics. For each pixel, it follows an imaginary “line” out from the viewer through that pixel into the computer world. Then it colors the pixel based on what the line hits. Unfortunately, it also takes a lot of computing power.
Matte spheres in different shades of grey. The blue in the spheres is reflected from the sky.
The motivation for this project was to learn how to make things run faster on a graphics card. I quickly realized (before I wrote a line of code) that I’d need the basic raytracer to be its own project. Having it run faster will have to be a job for another day!
A final demo scene, showing off reflectivity and metal surfaces.Note the pincushion distortion of the overall render, and striations on the ground.
a rough cut, blow, or stroke. (the work was accomplished one hack at a time)
a quick job that produces what is needed, but not well (this code is a hack, but it works!)
Hack-A-Day is challenge to make complete one new project, from scratch, every day in November 2023.
Last year (2022), I set myself the challenge to make a software project every day, and met it. I had a ton of fun, and make a lot of cool video games and projects I can show off. This year I’m inviting the rest of the world to join me!
I’m a programmer, so I’m doing a new computer programming project every day. But you can do any kind of project, whatever you pick is great.
I encourage you to join. I would guess this takes 2-4 hours a day (similar to NaNoWriMo). But if you don’t have that kind of time, please do still join for as many days as you can! And if you want to collaborate with me, set aside a free day and message me by email. My calendar is at zachary.youcanbook.me. Feel free to grab any day starting the 4th!
Left to right: Doomlings, Star Realms, The Mind, Chrononauts, FitzIt, Are you the traitor?, Are you a werewolf?, Hanabi, Set, Icehouse/Zendo rules, regular playing cards
I’ve noticed that board game boxes tend to be a little big. I combined five into one box:
Azul, Settlers of Catan, Clank, Concept, Nuclear WarThis is “portable” if you have a car trunk, maybe! It’s heavy as heck.
I made an animated HTML + CSS cheatsheet. This took me about three days. It is not really intended for beginners. It contains stuff I frequently forget myself.
In my recent campaign, I had a handout for the players. I took it out, and on a whim, I thought « a handout is boring ».
I tore it into quarters in front of their eyes. I wrote on back of the handout pieces “5“, “10“, “15“, “20“. “Make me an investigation check,” I intoned in my best DM voice. “I will grant you any pieces under your roll.“
They got 23, so I gave them all four scraps. They taped it back together and got the whole handout.
And they remembered that handout. They told players in other campaigns about the handout.
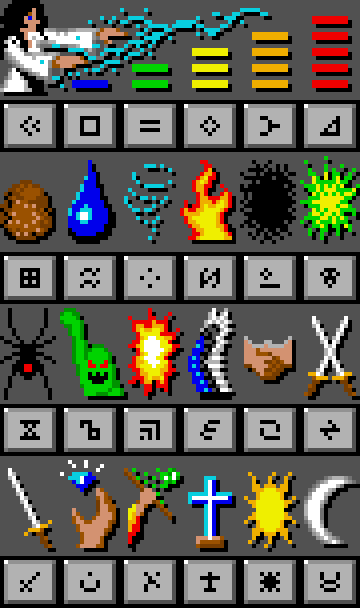
I’m a fan of the game Dungeon Master II (1993). In fact, I’m planning to get a tattoo of the rune system. So I looked around for a reference image. Here’s one from the game manual:
This looked like a nice one, because it shows the game graphics:
But there’s one problem–an entire row of runes is missing. Here’s a corrected one I made.
I’ve had a couple people ask how my TODO list works, so here’s what I’ve been doing for the last few years. I have four lists in total: a calendar, a yearly list, a daily list, and a master list.
A calendar.
The calendar has anything that needs to be done on a specific day. Birthday reminders, doctor’s appointments, and weekly activities like board game night or trash day. You’ve seen calendars. This is nothing interesting.
A yearly goals list
A yearly list of my goals for the year. I typically have 5-15 goals, and finish half of them.
This is mostly for motivation and focus. I don’t look at it much, and often only write it a third of the way into the year.
You can ignore this one.
Daily TODO list
A daily TODO list, written on paper. I throw it out at the end of each day, without copying anything off it. (I actually scan it, but I never look at the scans). This one I find very helpful.
Master TODO list
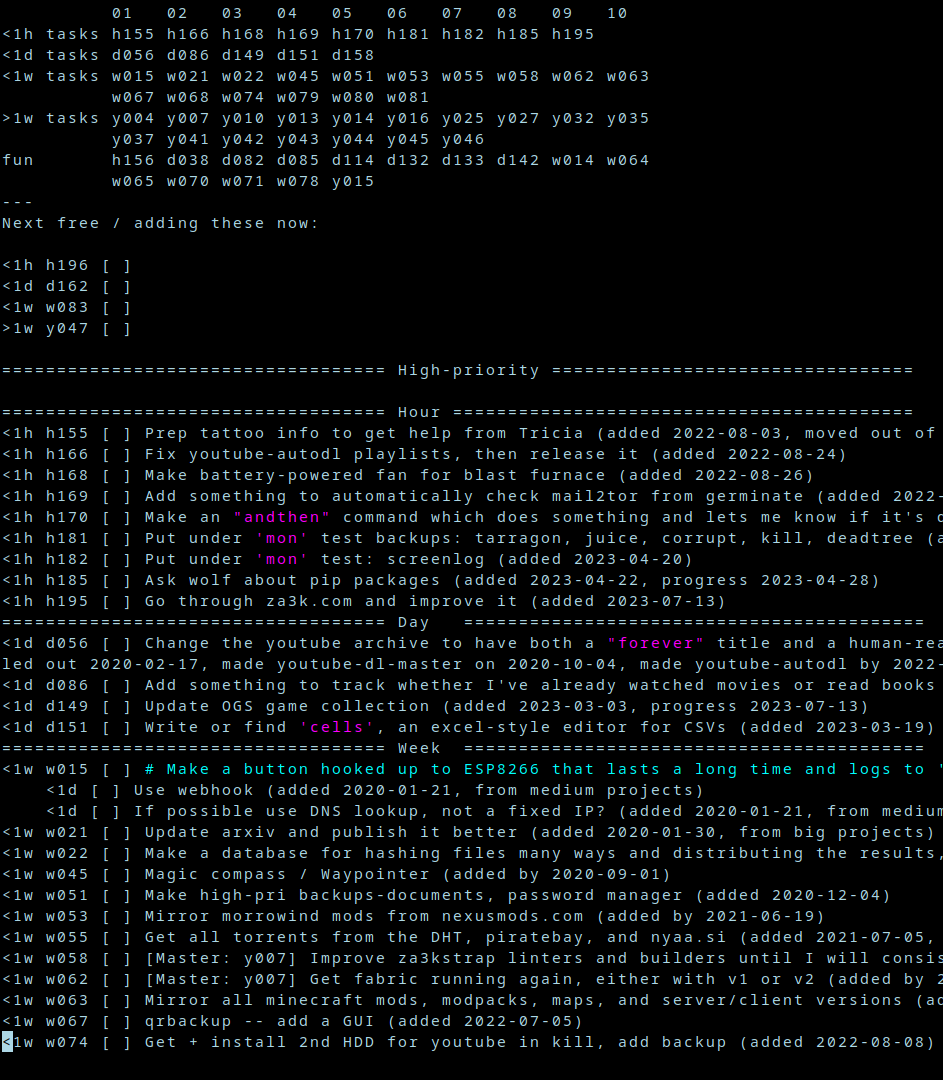
A “master” TODO list, consisting of everything I want to get done long term. I store this as a text file.
Each task is a one-line description.
I sort tasks into four categories:
Tasks that will take under an hour
Tasks that will take under a day (but more than an hour)
Tasks that will take less than a week
Tasks that will take more than a week
At the very top is just a list of all my task numbers, so I can see how many I have in each category, and skip down to them.
Tasks are marked as
[ ] Unfinished
[x]Finished (think ✅)
[X]Cancelled (think ❌, decided not to do it)
[/] Partially done (for very big tasks)
[>]Transferred to another system (doesn’t happen in the master TODO system, but sometimes I do this from my journal or a daily TODO list to indicate I wrote it down in the master TODO system)
In addition, I have a few special categories:
Urgent tasks. Sometimes I’ll have things that really need to get done soon (but not “today”, or they’d go on the daily list). Taxes often fit in here.
“Stuck” tasks. If I have no idea how to proceed with a task, it goes in a special category.
“Done” tasks. These are waiting to be archived (which is why everything you see is un-done)
“For fun” tasks. I try to keep a tasks which are just for fun in their own little section. Things like “learn to make ice cream”!
I try to minimize subtasks, in general. If I have a big task (clean the house), I’ll try to list it as “clean the bedroom”, etc as seperate tasks. If I have to, I’ll have a big task that references separate small tasks, but it’s the exception, and usually in the “more than a week” category.
I play D&D. There are a thousand initiative trackers out there. Here’s one I invented recently.
First, each player picks a Meeple to be their character’s mini.
Four PCs on a wagon move over swampy terrain.
Quick, roll initiative! The players all roll, and so do the enemies. We grab a second meeple for each player, as well as second token for each enemy. This becomes the initiative tracker.
This is the initiative order. It’s currently the red meeple hero’s turn. Next up will be the blue meeple hero, then the black cube enemy, and so on.