
I made a small game called Doodlemoji Alchemy, together with my friend Jennifer, as part of Hack-A-Day.
You can play it here.
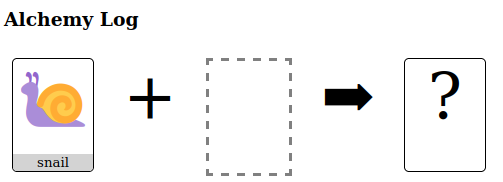
You combine elements to make something new. Sometimes you get an old element:

Sometimes you discover a new one!

I made a small game called Doodlemoji Alchemy, together with my friend Jennifer, as part of Hack-A-Day.
You can play it here.
You combine elements to make something new. Sometimes you get an old element:
Sometimes you discover a new one!
Today’s update is a short one. I ported my raytracer from day 02, to the Nvidia GPU: ha3k-06-raytracer
The visuals are pretty much the same. Incidentally I discovered the striations on the ground disappear if we increase the floating point precision.


Render on the GPU is 30x faster (0.05 fps -> 3 fps). That’s still not very fast.
I didn’t get video working yesterday, or anything else visually new. I will call this one a failure overall, because I have nothing interesting to show off. I learned stuff and made progress though, so it’s not so bad.
Here’s a working video!
Lashed furniture is made using sticks and rope or twine. Today’s project was to make one out of bamboo and brown paracord. The frame is shown–imagine boards or many pieces of bamboo forming a top.

We found this little $5 tool to be incredibly good for cutting bamboo. It’s designed for almost the same thing, cutting metal pipes.

It wasn’t bad for a first try. That said, we decided the top wasn’t flat enough to give a good finish, so the whole thing is going to be burned at the next bonfire.
Today I wrote a simple raytracer. A raytracer is a very simple way to draw excellent graphics. For each pixel, it follows an imaginary “line” out from the viewer through that pixel into the computer world. Then it colors the pixel based on what the line hits. Unfortunately, it also takes a lot of computing power.
Mine is based on the explanation (and code) from “Ray Tracing in One Weekend“, and the code from “My Very First Raytracer“.

The motivation for this project was to learn how to make things run faster on a graphics card. I quickly realized (before I wrote a line of code) that I’d need the basic raytracer to be its own project. Having it run faster will have to be a job for another day!

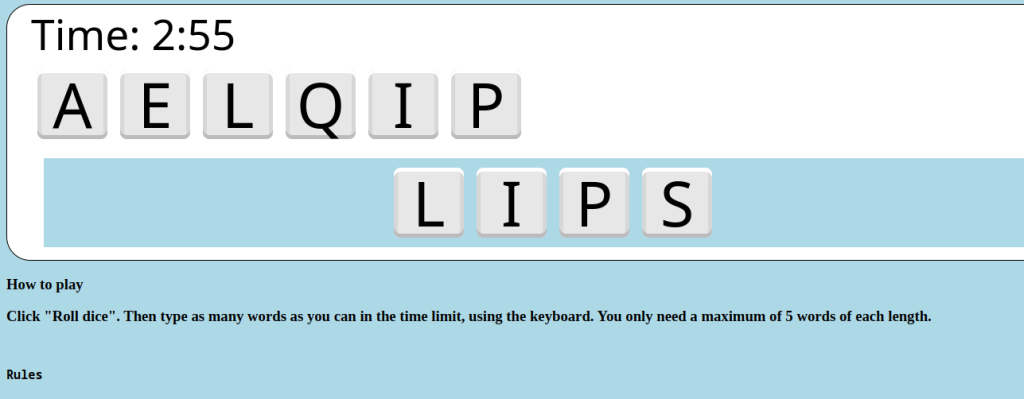
Today I chose to write a web version of a word game my family has loved for a long time, but which is sadly out of print.
It is meant to be played multi-player, but you’re welcome to try it out single-player online. Have fun!
Source code here
HACK (noun)
- a rough cut, blow, or stroke. (the work was accomplished one hack at a time)
- a quick job that produces what is needed, but not well (this code is a hack, but it works!)
Hack-A-Day is challenge to make complete one new project, from scratch, every day in November 2023.
Last year (2022), I set myself the challenge to make a software project every day, and met it. I had a ton of fun, and make a lot of cool video games and projects I can show off. This year I’m inviting the rest of the world to join me!
I’m a programmer, so I’m doing a new computer programming project every day. But you can do any kind of project, whatever you pick is great.
I encourage you to join. I would guess this takes 2-4 hours a day (similar to NaNoWriMo). But if you don’t have that kind of time, please do still join for as many days as you can! And if you want to collaborate with me, set aside a free day and message me by email. My calendar is at zachary.youcanbook.me. Feel free to grab any day starting the 4th!
My friend Callen taught me some Godot, and we made an Easel Toy. You combine colors to make other colors. Nothing fancy.

I condensed some of card games into one box:

I’ve noticed that board game boxes tend to be a little big. I combined five into one box:


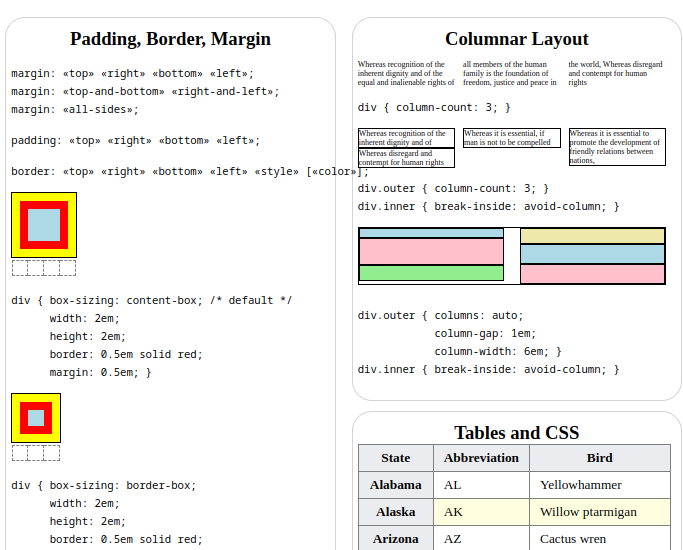
I made an animated HTML + CSS cheatsheet. This took me about three days. It is not really intended for beginners. It contains stuff I frequently forget myself.
In my recent campaign, I had a handout for the players. I took it out, and on a whim, I thought « a handout is boring ».
I tore it into quarters in front of their eyes. I wrote on back of the handout pieces “5“, “10“, “15“, “20“. “Make me an investigation check,” I intoned in my best DM voice. “I will grant you any pieces under your roll.“

They got 23, so I gave them all four scraps. They taped it back together and got the whole handout.
And they remembered that handout. They told players in other campaigns about the handout.