
There are 24 hours in a day. This shows you how many of those are daylight. You can use it as a calendar, or you can wistfully watch it, waiting for the sun to come back.
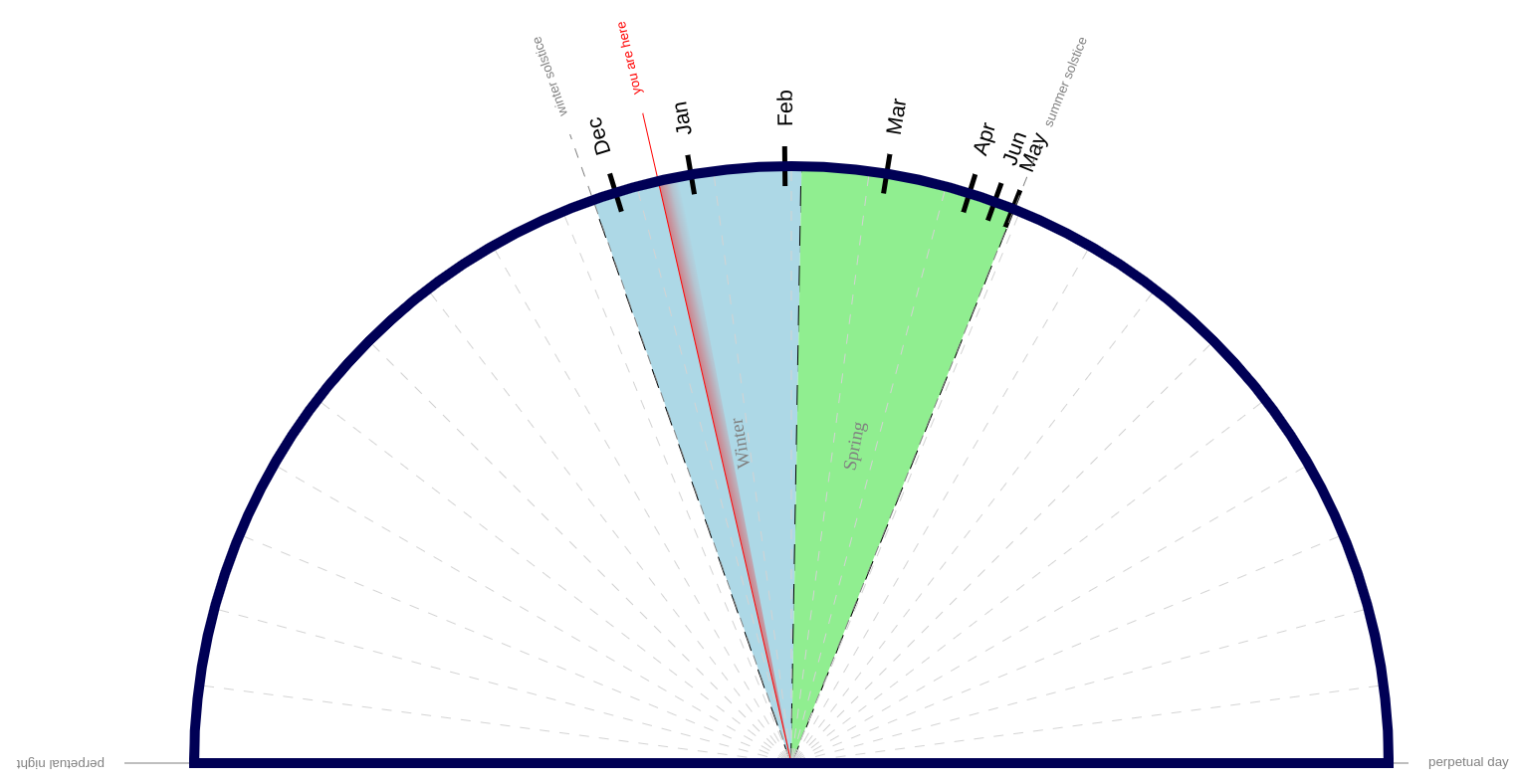
There are 24 hours in a day. This shows you how many of those are daylight. You can use it as a calendar, or you can wistfully watch it, waiting for the sun to come back.
I added some temperature sensors around my house.

The sensors run on AAA battery, and periodically transmit the temperature on zigbee, a radio protocol in similar frequencies as Wifi. The signals get received by a USB dongle designed to receive and transmit zigbee.

This is connected to a raspberry pi running zigbee2mqtt. The messages get sent to an mqtt broker via wifi. mqtt is a pub/sub protocol that runs over the internet. Any computer on my LAN can then be notified of temperature updates, by asking the mqtt broker to send them updates.
I wrote a small server which stays on all the time, listening to updates and recording changes to a database. It also generates reports periodically.
I think my database format is mildly interesting, in that it's designed to use a fixed amount of space. Anyone who wants to see the technical details, can check the github repo, specifically this file.
Temperatures can be seen in celsius or fahrenheit online. An example in Fahrenheit is below.
Current Temperature
last updated: 2024-11-07 8:34pm
Sensor Temperature Humidity Last update
Outside - Front 51.51°F 69.86% 1 minutes ago
Outside - Back 64.26°F 99.99% 22 hours, 49 min ago
Upstairs - Dining Room 69.67°F 53.24% 0 minutes ago
Upstairs - Bedroom - Za3k 71.35°F 60.15% 21 minutes ago
Upstairs - Bedroom - Master 68.90°F 58.11% 4 minutes ago
Upstairs - Kitchen 71.20°F 50.50% 6 minutes ago
Upstairs - Garage 65.55°F 60.65% 2 minutes ago
Basement - HVAC/Server 68.02°F 51.27% 3 minutes ago
Basement - Workshop 67.10°F 52.91% 14 minutes ago
-------------
Hourly Temperature
last updated: 2024-11-07 8:34pm
outside inside
2024-11-07 8am 54.49°F 69.44°F
2024-11-07 9am 53.81°F 69.04°F
[...]
2024-11-07 6pm 56.11°F 69.86°F
2024-11-07 7pm 53.53°F 69.65°F
-------------
Historical highs and lows
last updated: 2024-11-07 8:34pm
outside inside
2024-11-07 51.51 - 64.15°F 67.06 - 81.54°F
2024-11-06 61.21 - 71.24°F 68.36 - 81.18°F
[...]
2024-10-10 49.39 - 60.89°F 67.59 - 77.49°F
-------------
Code: https://github.com/za3k/temp-monitor
Having tested out zigbee and mqtt, I felt ready for my actual use case -- curtains. I live across the street from a major parking lot, and they have floodlights on all night. To sleep, I need blackout curtains. The problem is, it's pretty hard to wake up with blackout curtains drawn.
My solution was to get some smart curtains, and have them automatically go down at the end of the day, and go up in the morning.

This worked fine, after I got the curtains set up. I've completely forgotten about them, which is exactly how I like my home automation--I want to never think about it. For more about how to set up IKEA smart curtains, see my notes. It comes with 6 manuals.
blinds controls my blinds via the computer, and mqtt2mqtt allows my IKEA remote to control them too. cron and heliocron automatically open and close the curtains on a timer.
I worked on monitoring power usage via my circuit breaker with current transformers and the circuitsetup ESP32 energy meter but it's currently stalled. The main problem is that I can't fit the CTs into my circuit breaker. If I get it working, I'll post an update.
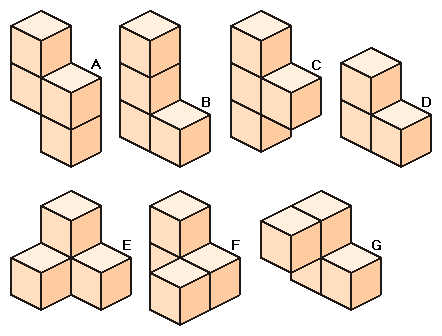
Today I tried to design a laser-cut set of Soma cube pieces. The pieces (shown above) are (conceptually, and sometimes actually) made of 3D blocks glued together.
I've seen a particular style of joinery for acryllic, called finger joints. Those looked easy to cut and easy to put together (if hard to design).

I wrote a python script that takes a description of a piece, like this:
Piece E
xx x-
x- --
-- --
And draws all the flat faces I need to cut.

I was already running far behind, time-wise. I ran out of time before I could get the joinery working. Honestly, I don't think I'm very close, either.

How to do a three-piece corner join was especially confusing me.
I've changed the backend of my blog. You shouldn't notice any differences, except that comments are disabled for the time being.
All links to the site should continue to work.
If you notice any problems, even small ones, please send me an email.

Lately I’ve been messing about in Godot, a framework for making video games (similar to Unity).
I wanted to make a 3D game. In my game, you live in a geodesic dome, and can’t go outside, because mumble mumble mumble poisonous atmosphere?.
A geodesic dome, I learned, is related to the icosahedron, or d20 from RPGs.


A simple dome is the top half of the icosahedron. As they get more complex, you divide each triangle into more and more smaller triangles.
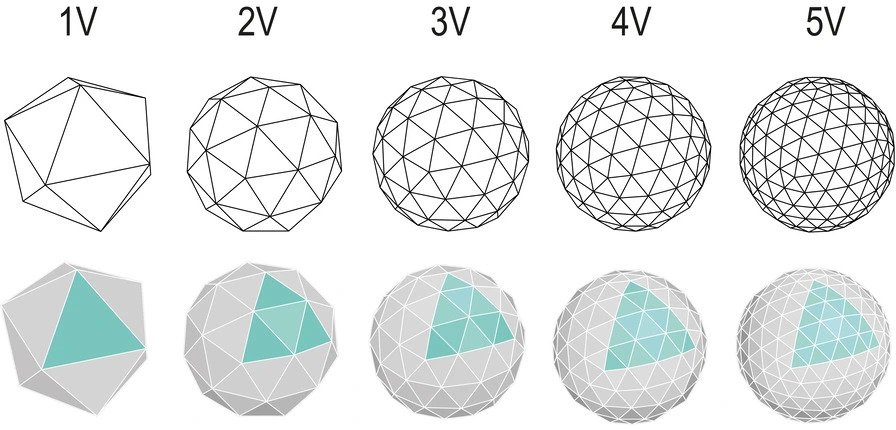
So to make a nice geodesic dome, we could find one (I failed), make one in Blender (too hard), or use some math to generate one in Godot. And to do that math, we need to know the list of 20 icosahedron faces. Which basically just needs the list of the 12 vertices!
Now, obviously you could look up the vertices, but I thought of a more fun way. Let’s put 12 points on a sphere, make them all repel each other (think magnetically, I guess), and see where on the sphere they slide to. Maybe they will all be spaced out evenly in the right places. Well, here’s what it looks like:
So… kinda? It was certainly entertaining.
By the way, the correct coordinates for the vertices of an icosahedron inside a unit sphere are:
Sometimes Linux wants to open files. I mostly use the command line, so I wrote some helper programs to open things in terminals.
open-text-file opens your default text editor in a terminal. I set it as my program to open all text files.open-directory opens a terminal with that working directory. I set it as my program to open all directories.They’re both available in short-programs. Both default to xterm.
When you click an email address, it automatically opens in your email client. But I don’t have an email client, I use webmail. I wrote a custom handler for Linux.
First write a program to open mailto links. Mailto links look like “mailto:me@mail.com” or maybe even “mailto:me@mail.com?subject=mysubject&body=mybody“. Test it by hand on a few links. Mine (mailto-opener) composes a new message using my webmail.
Next, write a desktop file for the opener. Here’s one:
#/usr/local/share/applications/mailto-opener.desktop
[Desktop Entry]
Type=Application
Name=mailto: link opener (github.com/za3k/short-programs)
# The executable of the application, possibly with arguments.
Exec=/home/zachary/.projects/short-programs/mailto-opener %u
Note the %u in the Exec= line. That’s required.
Now update your system mimetype database. On my Arch Linux install, I run
xdg-mime default mailto-opener.desktop x-scheme-handler/mailto
Finally, restart your browser. Really. Firefox and Chromium/Chrome both cache mimetype openers.
A related opener I added recently was for magnet links, such as are popularly used for bittorrent.
~ $ cat /usr/local/share/applications/transmission-remote.desktop
[Desktop Entry]
Type=Application
Name=transmission-remote magnet link opener
Exec=transmission-remote <TRANSMISSION INSTANCE> -a
transmission-remote is the name of a command-line Linux program. It connects to an instance of Tranmission (a popular torrent client) running on another machine.
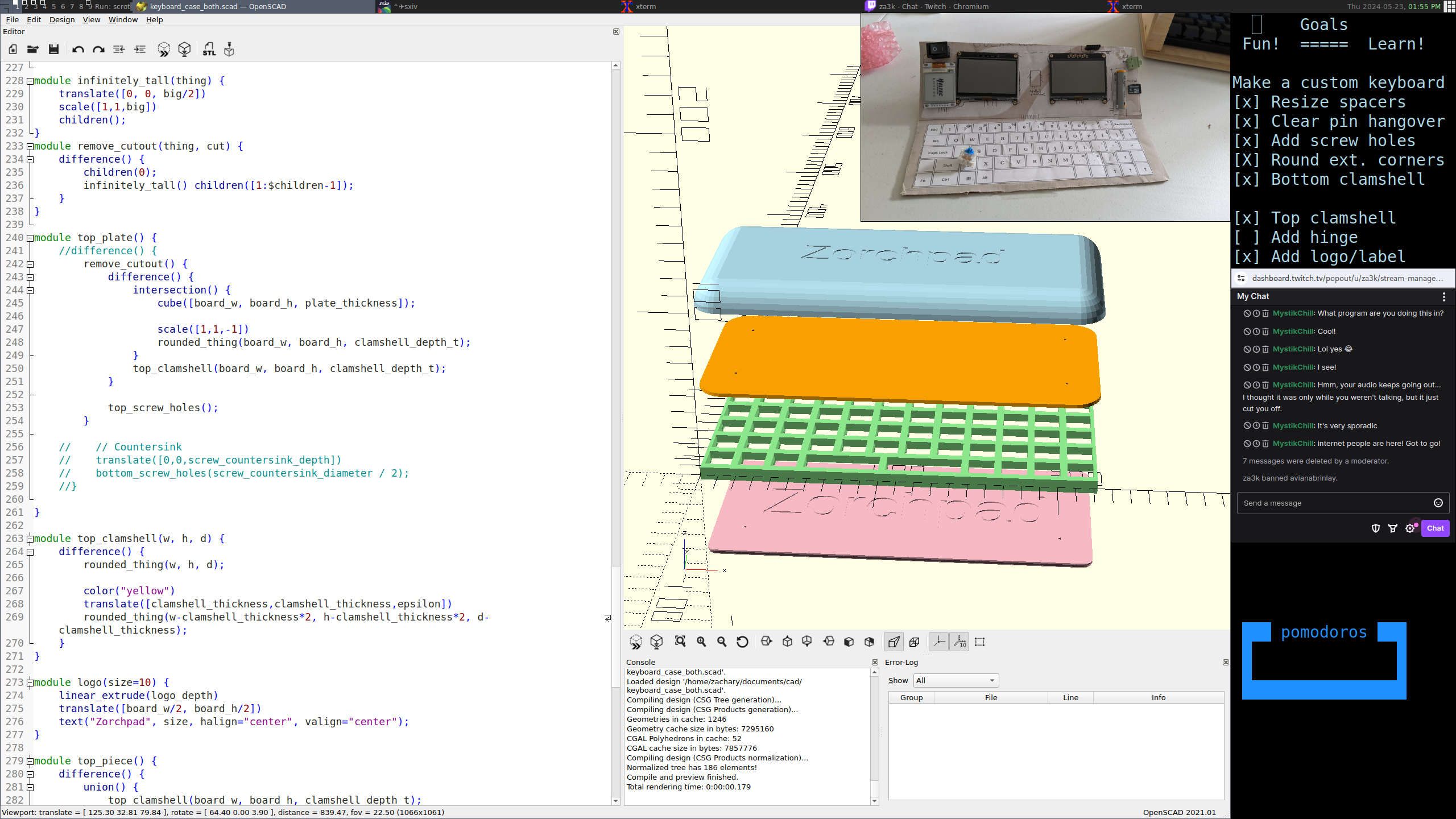
I’ve been designing a keyboard and case for the zorchpad.
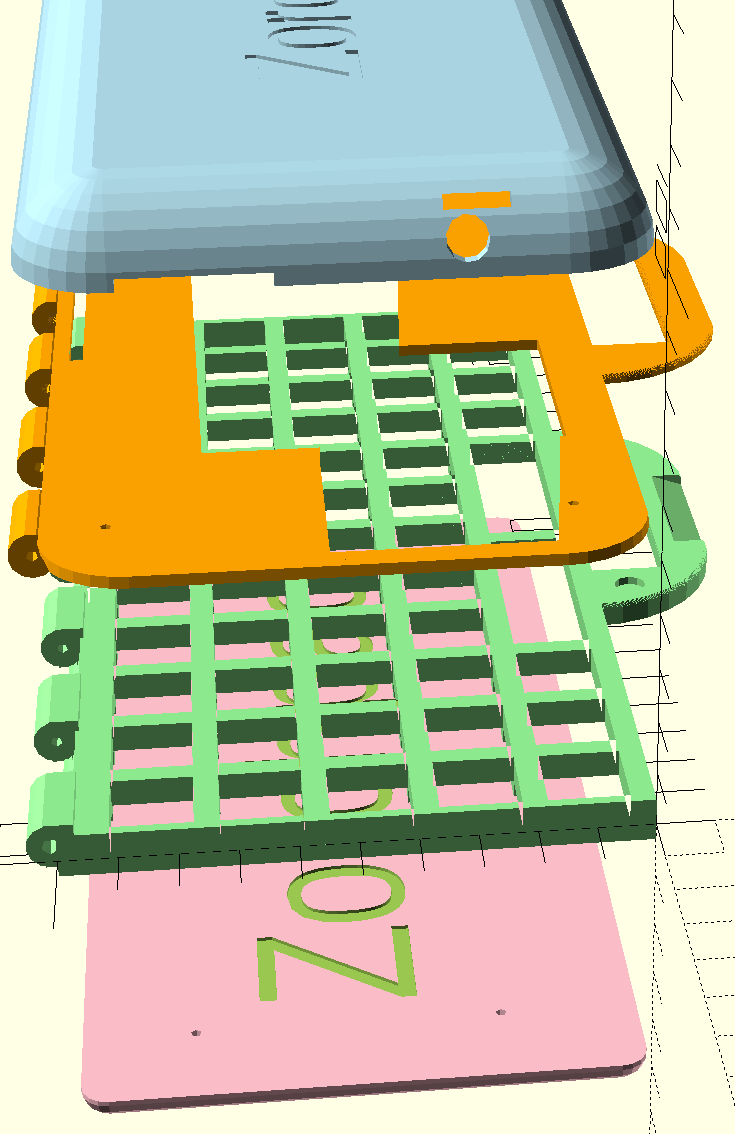
There are four pieces in the first iteration.

A top bottom base, to enclose the keyboard electronics.
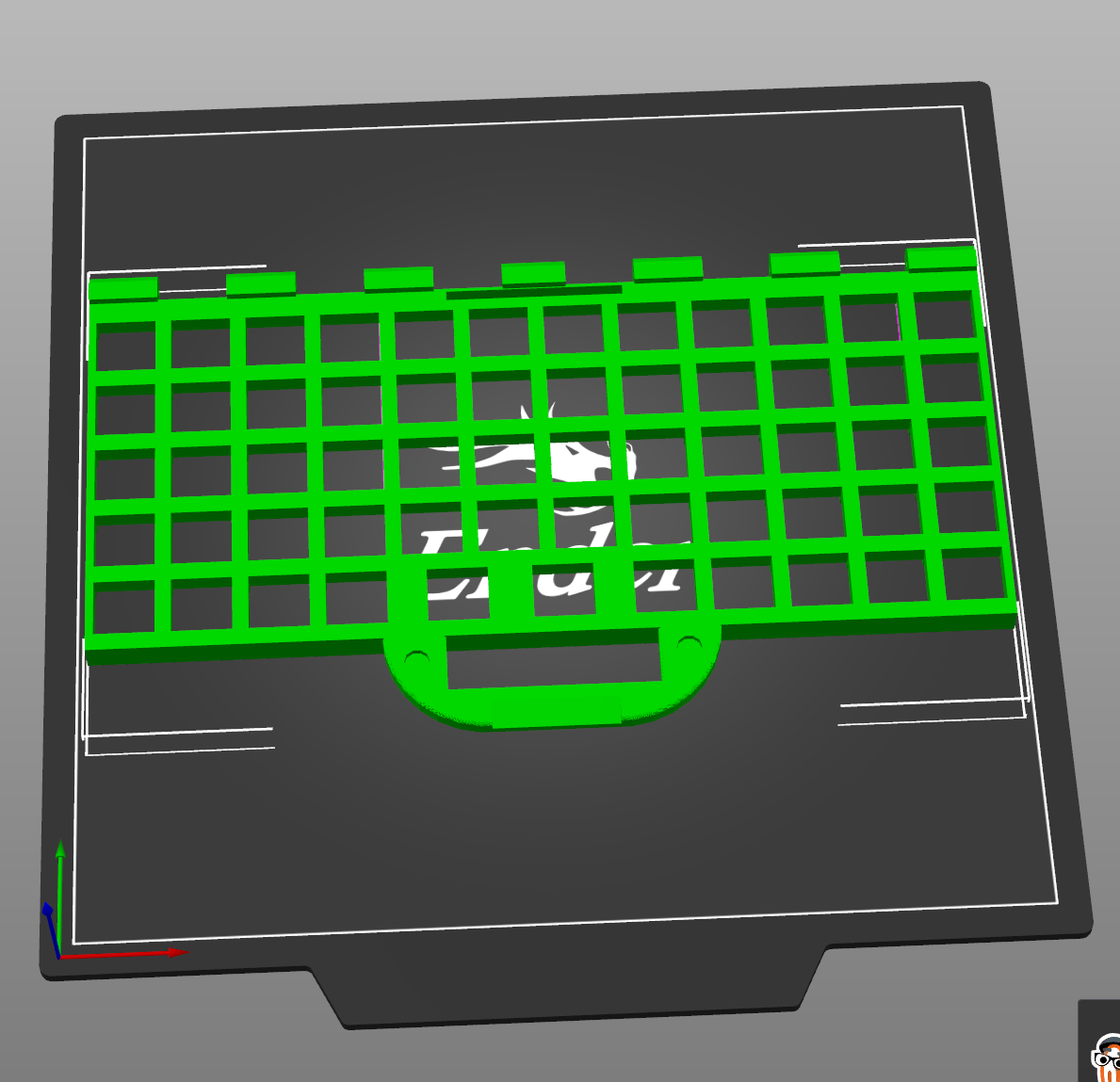
A keyboard plate. The keys fit into the holes here. You type on the top, electronics go in the bottom.
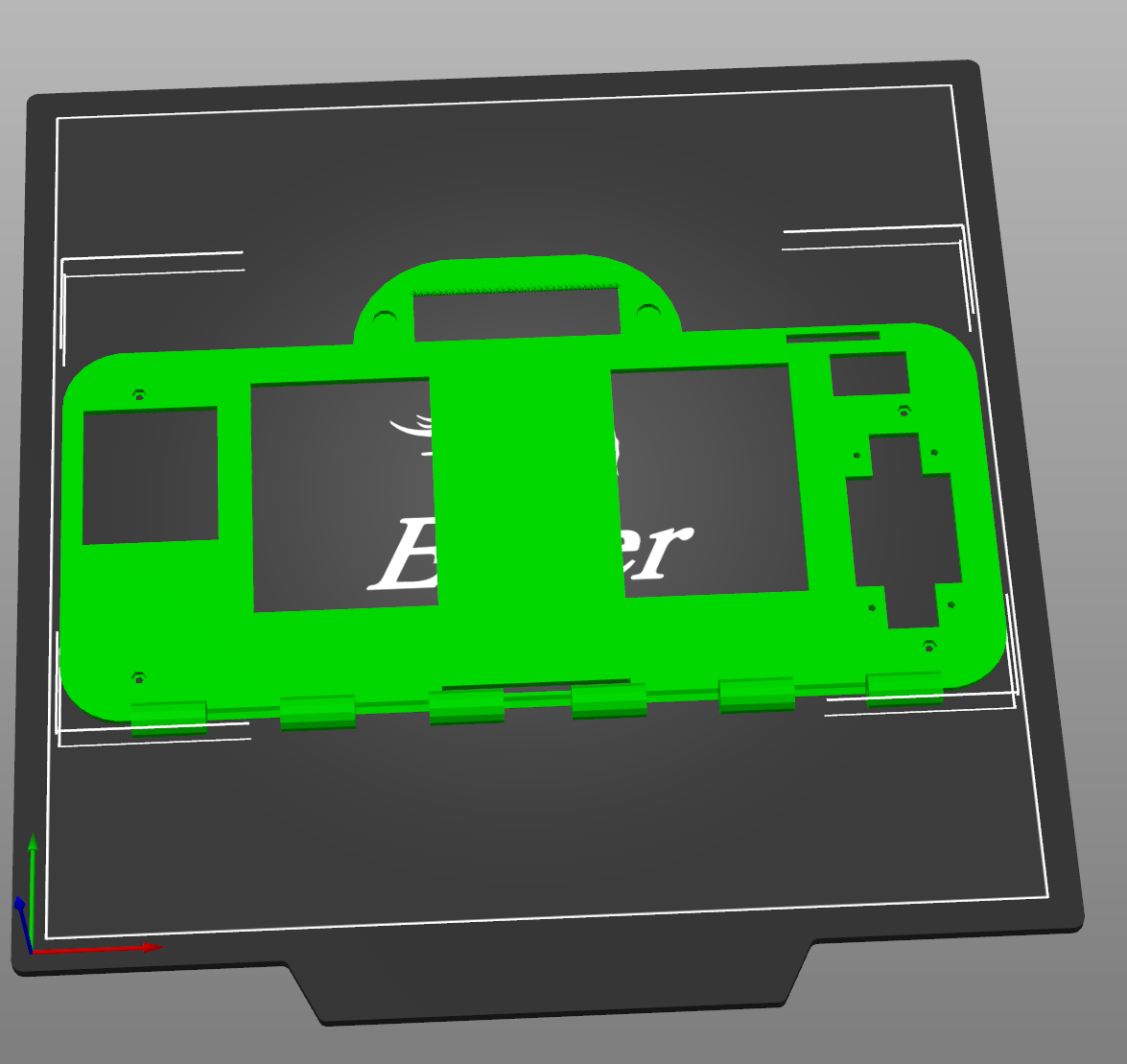
A top plate. You see the screens, and switches through the cutouts. Otherwise, it keeps the behind-the-scenes wiring out of sight.

And finally, the top piece.

Here are the pieces in correct position. In the top will be the screens and battery. The bottom is a keyboard you type on. The whole things is meant to fold on a hinge, much like a laptop.

The same pieces, spread out.
There were many, many problems with the first design and the first print. I’ll talk about them (and my fixes) in my next post.
The Zorchpad needs a custom keyboard. Its power budget is only 1mW, and there’s just nothing available in that range. So, I need to make a custom keyboard. I started reading up on how to make your own–especially the electronics.
I don’t know how to make a PCB:

Or how to attach headers to the inside of an existing keyboard, which looks like this–:

But I found a project called GOLEM with an excellent guide to making your own keyboard. Here is their wiring:

I can do that! They got me out of a major rut.
Their advice walks you through how to do a small keyboard in a cardboard plate. I did a few keys, gauged the effort, and decided to use my 3D printer. Cutting out 50-60 keys precisely by hand doesn’t sound easy. Worse, if you mess up, you have to start over. In plastic, I can’t mess up halfway, and the spacers to support the keyboard can be part of the print.
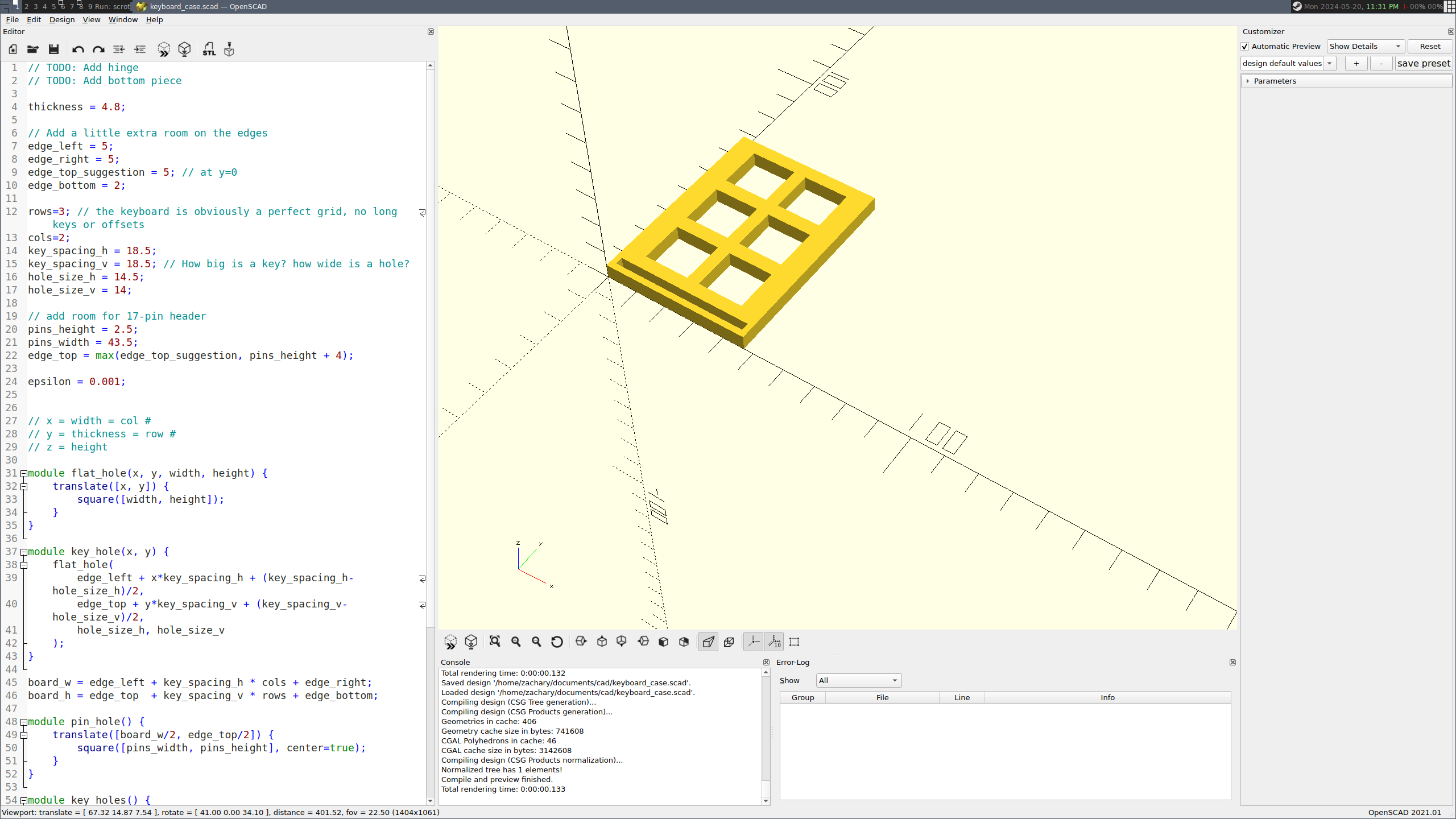
Above, I’m designing a “sampler” keyboard in CAD (OpenSCAD). I want to iron out problems in my process before I try a full-size keyboard. Below, Prusa-Slic3r is slicing the finished model for my 3D printer to print.
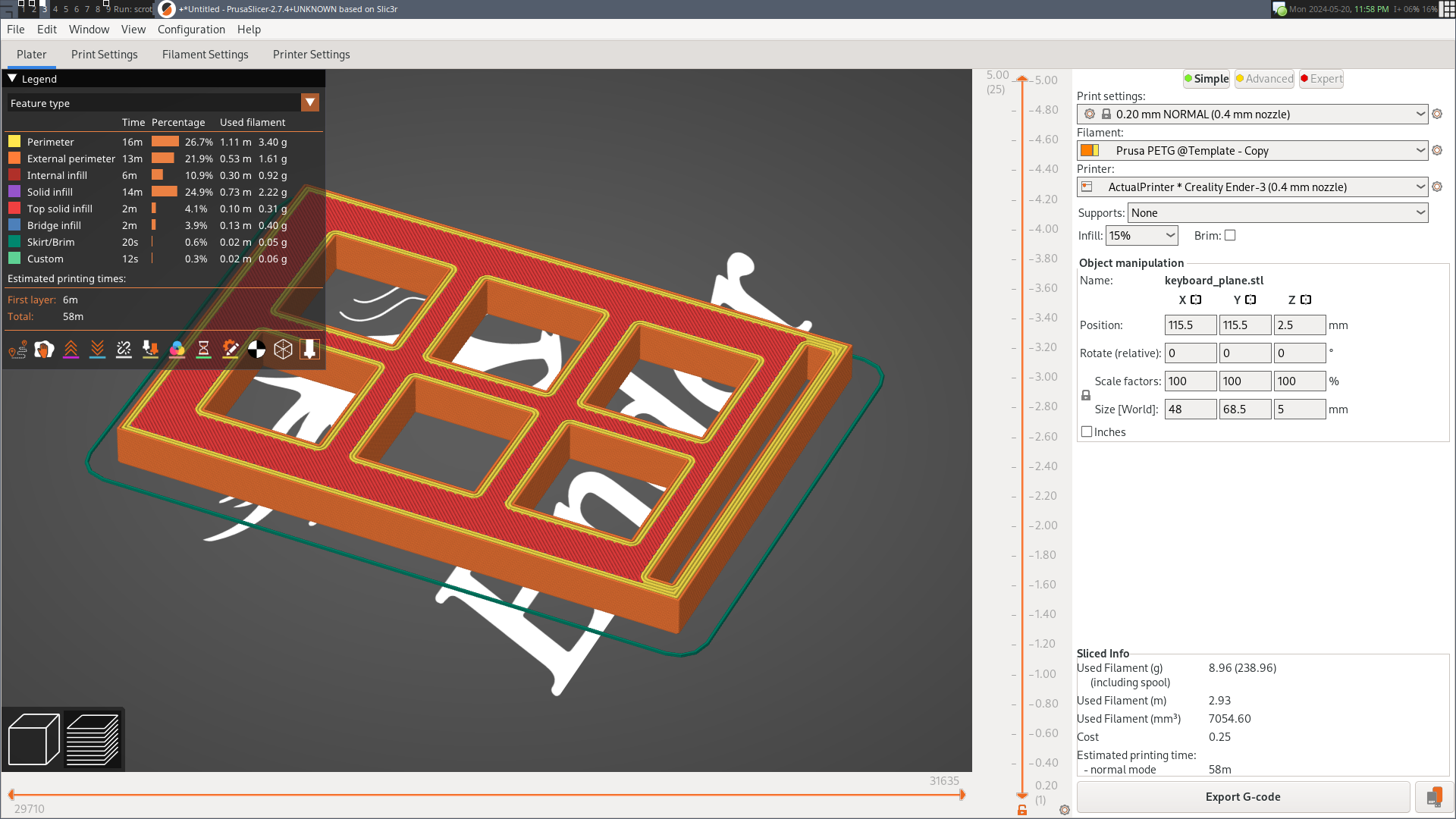
Here’s the finished sampler keyboard:

Currently I’m waiting on keycaps and switches ordered from China, and then I’ll put together my finished keyboard. But I have been making some progress in the meantime. Here’s the layout I’m going to try.

And I’ve started streaming some development of a case and keyboard on Twitch (Tue/Thu 12pm noon, EDT). Feel free to join! Anyone can watch, but you need an account to chat.
My friend Callen tried to help me run a DC motor to roll my curtains up and down. We didn’t make a ton of progress, but we had some fun making a little music.