A friend of mine, Kragen Javier Sitaker has been designing something he calls the zorzpad (see link below). I can never remember the name, so as a joke my version became the “zorch pad”. We live on opposite sides of the globe, but we’ve picked up the same or similar hardware, and have been having fun developing the hardware and software together.
The basic idea of the Zorchpad is to have one computer, indefinitely. It should keep working until you die. That means no battery that runs out, and no parts that go bad (and of course, no requirements to “phone home” for the latest update via wifi!). This is not your standard computer, and we’ve been trying a lot of experimental things. One of the main requirements is that everything be very low-power. He picked out the excellent apollo3 processor, which theoretically runs at around 1mW. In general, the zorchpad is made of closed-source hardware.
Since I’ve realized this will be a long project, I’m going to post it piece-by-piece as I make progress. Below is a demo of the display.
The graphics demo shows, in order:
a title screen
a flashing screen (to show graphics-mode framerate)
a demo of font rendering. we’re using the fixed-width font tamsyn.
We’re using a memory-in-pixel LCD. The only manufacturer is Sharp LCD. You have have seen these before in things like the Pebble watch–they’ve very low-power except when you’re updating. This particular screen is quite tiny–240x400px display (which is fine with me), but only 1.39×2.31 inches (35x59mm). The only bigger screen available in this technology is 67x89mm, a bit lower resolution, and out of stock. As soon as it’s in stock I plan to switch to it.
According to the datasheet, the screen consumes 0.05-0.25mW without an update, and perhaps 0.175-0.35mW updating once per second. We haven’t yet measured the real power consumption for any of the components.
The most obvious alternative is e-ink. E-ink has a muuuch slower refresh rate (maybe 1Hz if you hack it), and uses no power when not updating. Unfortunately it uses orders of magnitude more power for an update. Also, you can get much larger e-ink screens. The final zorchpad might have one, both or something else entirely! We’re in an experimentation phase.
Datasheets, a bill of materials, and all source code can be found in my zorchpad repo. Also check out Kragen’s zorzpad repo.
Infocom introduced (AFAIK) the concept of feelies:
[…] Imaginative props and extras tied to the game’s theme—provided copy protection against copyright infringement.[45] Some games were unsolvable without the extra content provided with the boxed game. And because of the cleverness and uniqueness of the feelies, users rarely felt like they were an intrusion or inconvenience, as was the case with most of the other copy-protection schemes of the time.[49] Feelies also provided the player with a physical aspect to the gameplay of their text adventures, giving another dimension of strategy to what would other-wise just be a text parser.
– Wikipedia (Infocom)
I love to give out feelies for my D&D campaigns. Here are some lil handout props I made:
As a programmer, one task I have to do often is estimate how a long a task will take. But as a programmer, most tasks I do have never been done before, and will never be done again, so estimating how long they will take is a little tricky. Here are some tips I’ve learned over the years.
Always use clock time.
Yes, there are interruptions. You need your coffee. You didn’t get around to it that day. You want to know those things in your estimate, too. Just use the time on the clock for when a task starts and ends.
This is especially important if you’re self-employed.
Write down how long you think a task will take. Afterwords, write down how long it took.
This simple step is the most important one. This gives you a clear idea of exactly what a task is and when it’s done. It also starts automatically training your brain.
You’ll start seeing patterns. You consistently underestimate how long everything will take. Conversations take longer than they feel. Exercise takes less time than it feels like. Fixing problems is highly variable. Doing something from scratch is easier to predict.
Play a game. Predict things as well as possible.
Don’t change how you do them. You win if you guess accurately.
Use as few units as possible.
Don’t use minutes, hours, days, weeks, and months. Personally, I try to use minutes and hours for everything. Of course, when I report to my boss, I convert to days, but in my own notes I estimate things in one unit.
Learn your multiplication factor.
How long will it take you to do a project? Well, last time you had a similarly-sized project, you thought it would take 2 hours, and it actually took 14 hours. Your multiplication factor is about 7x. So this time if it feels like a 3 hour task, plan for 21 hours.
Assume there’s only one multiplication factor for one kind of work (one kind of work like your entire job, not one type of task). You can have different ones for different time scales, though (minutes vs hours vs days vs weeks).
You can measure other peoples’ multiplication factor to figure out when they’ll actually be done with tasks, but I suggest doing it quietly and not mentioning it.
Credit: Folk, but credit to Joel on Software for the idea of estimating it for each team member
To estimate a long task, break it up into pieces, and add up the pieces.
Do this if your task takes 2 days or more. Because of the multiplication factor, carefully budget time for added tasks, things you forgot, problems, etc. Or you can skip it. Just consistently pick one.
Some tasks are more variable. Saying “something will take 1 hour” is vague. Saying “something will almost certainly take between 30 minutes and 4 hours” is more precise. How big should that range be? That’s called a credible interval.
Train your credible intervals. I trained mine using bug fixing, something which happens several times a day, is hard to predict, and you have little control over (you can’t “call it done” early). Customer calls could be another great candidate.
I trained on bugfixes using 50%, 90%, and 99% intervals. There are specific mathematical scoring rules, but basically if something is in your 50% interval more than half the time, narrow it; if your interval is correct less than half the time, widen it.
Credit: Eliezer Yudkowsky (personal website, no longer up)
Contents:
First-aid kit contents, 1x large red bag
Left pocket, survival:
Compass, Small Magnetic
String
Magnesium rod (under compartment) - Use with knife if lighters run out
Misc fasteners and bags (in bag)
Water purification kit. Good for about 3 person-years.
Work gloves
Right pocket, convenience:
Baby Powder - Prevents chafing. Also consider moleskin.
Earplugs
Floss
Face mask - For smoke or disease.
Glasses, spare, for Zachary
Lighter
Nail clippers
Petroleum Jelly - Chapped lips, protect wounds, help light tinder.
Razor
Sleeping mask
Toothbrush
Toothpaste
Center compartment:
(right) Band-aids/plasters, various sizes - Use to cover small cuts
(right) Gauze and medicine directions
(bottom pocket) Grill lighter
(back) covid-19 test
Thermometer, mouth
Tweezers
Alocane-brand Lidocaine burn relief gel
Triple Antibiotic Ointment (may not work) - contains bacitracin,
neomycin, polymyxin. Prefer washing using sanitation bag.
Hydrocorozone cream - treats itch and rash
Cotton swabs (in bag) - Clean wound
Gauze (in moleskin) - Wrap to stop bleeding, or use to clean a wound
Gauze (loose)
Moleskin - Patch blisters or prevent them from forming
Liquid Skin - Superglue. Disinfect small cuts, then brush on to close.
Q-tips - Clean wound
Sanitation bag (see below)
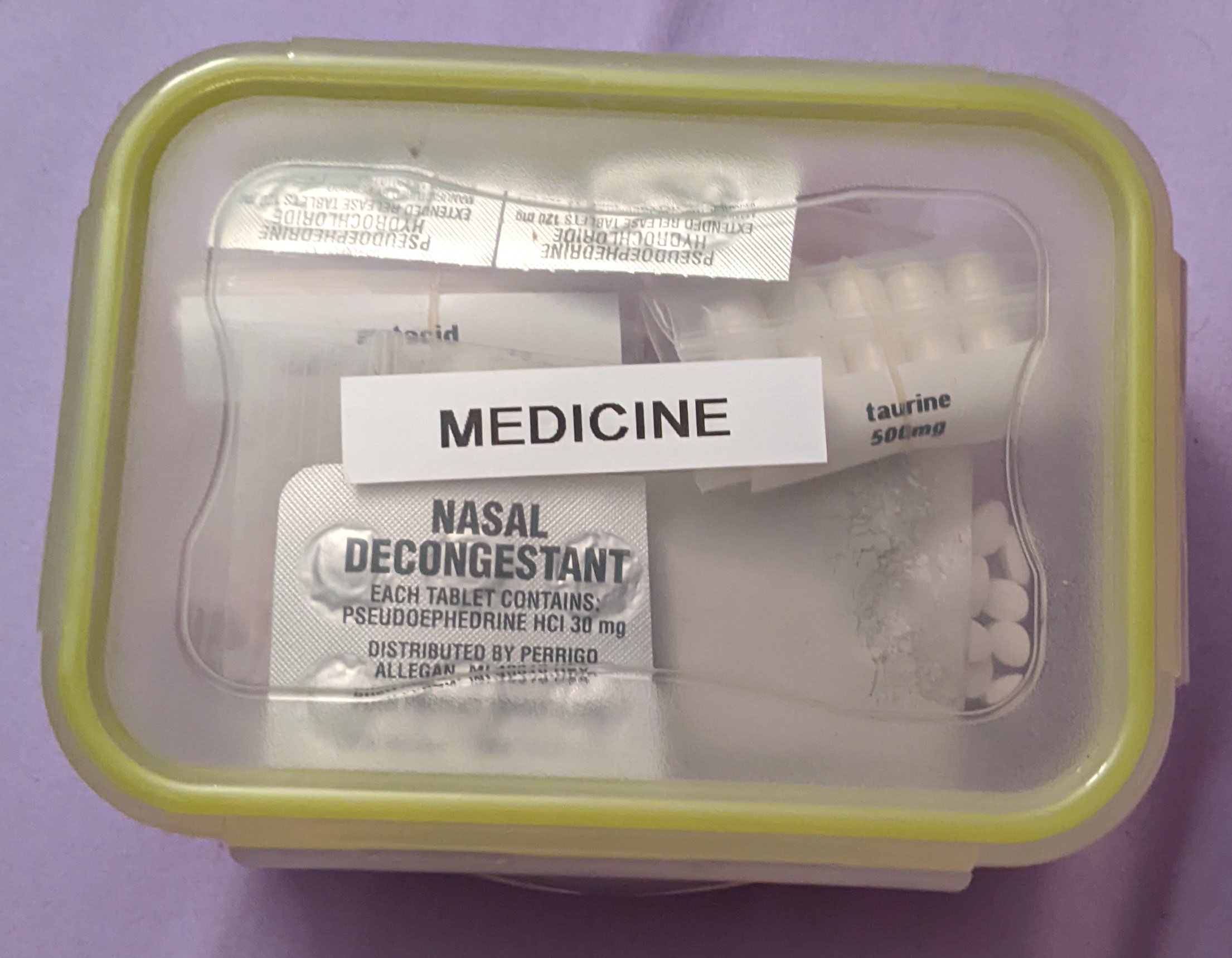
Medicine box (see back)
Vitamins box (see back)
Sanitation bag (in center compartment):
Water - Clean wounds. Slightly soapy. Refill and add campsuds and
povodone iodine to replenish.
Campsuds - Concentrated soap.
Povidone iodine - Use with water to create a sterile cleaning fluid.
Doesn't work to sanitize water (need 15min+80 drops/gal)
-------------------------
Medicine box (in center compartment):
Acetaminophen, 500mg, x20 - Longer white pill labeled 5500.
Non-NSAID pain medication. Does not reduce fever, only reduces pain
Use for people on certain medications or for headache.
Caffine, 200mg, x10 - Medium ycircular yellow pill labeled 44 226.
Take half with taurine to stay awake. Caffine impairs judgement
Calcium carbonate, 0.5g, x5 - Pastel colored large circular pills.
Antacid. Use for heartburn.
Ibuprofen, 200mg, x30 - Small circular red pill labeled I-2.
NSAID anti-inflammatory. Use to reduce fever or inflammation.
Low fevers fight diseases, don't remove them.
Loratadine, 10mg, x30 - Small oval white pill labeled L612.
Used to minor allergic reactions.
Melatonin, 3mg, x10 - Small unlabeled white pill.
Natural sleep aid. Take 1 to sleep somewhere noisy. Groggy after.
Peptobismol, x16 - Larger pink circular pill in plastic labeled RH 046.
Use for diarrhea or stomach upset. Recommended dose is 2.
Pseudoephedrine HCl, 120mg extended release, x2. One per day.
Pseudoephedrine Hcl, 30mg - One every 2-4 hours as needed.
Use for stuffy nose. Stimulant.
Taurine, 500mg, x5 - Medium white gel capsules. See caffine.
Razor blade, x1
Activated charcoal - Black powder.
In case of poisoning, immediately induce vomiting.
Then eat activated charcoal.
Bentonite clay - Grey powder. Do not use.
Vitamins box (in center compartment):
Mulivitamin, x20 - Large green pill labeled 1.
Take one every other day only if vitamin deficient.
Contains enough: Vit A, Vit C, Vit D, Vit E, Vit K, B1, B2,
Magnesium, Zinc, Selenium, Copper, Manganese, Chromium
Bayer One a Day Men's Pro Edge
Vit D, 5000 IU, x25 - Small yellow gel beads.
Take one every 2-3 days if sick or missing sunlight.
Zinc, 50mg, x20 - Medium white unlabeled circular pill.
Take half a pill per day to resist getting COVID-19 or for diarrhea
Folate, 400mcg, x20 - Small-medium white gel capsule.
Take one every other day if missing vegetables in diet.
Vitamin C, powder
Take small amounts if missing fruit from diet to prevent scurvy.
For diarrhea, oral rehydration solution. If not available, use water.
0.5tsp salt 6tsp sugar
0.25tsp potassium salt 1L/quart water
Potassium chloride, powder - ORS
Iodized table salt, powder - ORS or dehydration.
Atorvastatin, 40mg, x50 - Medium white oblong pill labeled ATV40.
Prescription: Take one pill daily to reduce cholesterol.
Here’s what happened in 2022 for me!
Move
I moved from California to Ohio. I wanted to be with my friends. Also, my old place caught on fire (twice). The new place is cheap, but underground. The first order of business was installing lots of lights, and replacing my moldy old mattress.
My dad kindly lent me a car until mine showed up in September. There was lots of DMV paperwork. Not the best, but Ohio is much cheaper and easier than California in this regard. I also got health insurance, which cost almost as much as my rent.
Happily I already knew many people where I was moving, and I also started attending several meetups from meetup.com. I got to spend Thanksgiving and Christmas with friends and family this year. I also sent out Christmas cards for the first time.
Games
I started two D&D games in 2022. One ended before session 1, the other exploded after two months. I had a nice time playing as a player in “Index Card RPG”, though. I ran a session of lexicon, which went pretty well. We quit before getting to the letter Z, but that’s a design flaw in Lexicon–it’s way too long.
I participated in the 2022 April Fools Puzzle Contest, on #ircpuzzles. I came in 7th.
This and that
A little travel. I went to Missouri to visit friends. I got to go to my friends’ wedding in Boston.
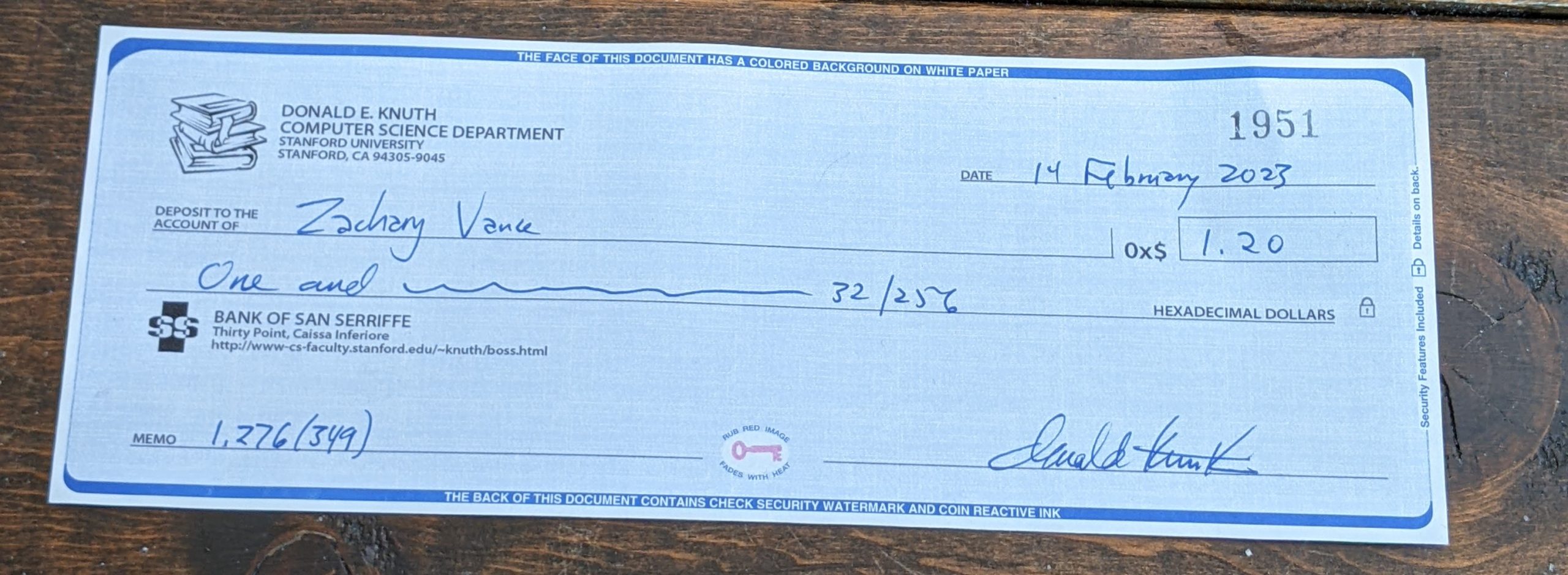
I read “The Art of Computer Programming” volumes 1 and 2. Donald Knuth sent me a check for finding a 0x1.2 bugs.
I got a snakebite lip piercing.
I made a first-aid kit, which I’m realizing I didn’t write up. My thinking was that it’s bad to give medical advice when you don’t know anything about medicine.
I made a new blast furnace with my sister, which we never used (old one).
In November, I did Hack-a-Day, a project I conceived to do a new computer project every day of the month that I could show off to others. As part of it, I learned web sockets, webRTC, unity3D, game programming. In all, there were around 30 projects–click the link to see them all.
I made huge improvements to qr-backup. Its basically “done” for the CLI version.
I wrote youtube-autodl, a program to automatically download a feed of youtube videos and sort them into folders.
I wrote a video linter for my personal video collection.
I wrote a screenshotter, which takes one screenshot a minute of my laptop (encrypted) and archives them indefinitely.
I was exercising daily. I kind lapsed after my ankle surgery, oops.
I stopped doing my daily morning log at some point, and didn’t fix it within 2022.
I tried an experiment with “no-computer” sundays. This was super productive one time, and less so the next. It led to the e-ink laptop, because writing a short story by hand was really painful.
I started limiting myself to one youtube video per day. That went great and I’ve kept it up.
I sorted my scans into folders. I decided not to do the whole process (transcribe the handwritten documents, etc) for the thousands of scans, because it wouldn’t be worth the time. I’ll wait and see what I can do with AI in a few years, maybe.
Writing
You can read most of what I wrote here! On a blog! Of particular interest might be my new index page.
I also wrote a short story, Earth II. It’s not online because it’s bad.
I had to remove library.za3k.com because of DMCAs.
The April Fools Puzzle Contest is over. Congrats to the winners.
Every year, the libera IRC network has a puzzle contest starting on 04-01. (It’s not an april fools joke). It’s fun but quite difficult.
This year I wrote about a third of the puzzles. Give them a try, either alone or as a team! It will be open indefinitely, but social activity will die off in a week or two.
As of writing, no one has won (finished all the puzzles) just yet.
I’ve been working on a spell guide for D&D games. During the process, I researched the differences between the Dungeons and Dragons 5e Player’s Handbook (PHB) and the 5e System Reference Document (SRD).
For those that don’t know, in 3e Wizards of the Coast released the core rules of the game for free. They’ve continued to do so for 3.5, 4, and 5e. The 5e rules were released under Creative Commons recently (thanks!), in response to some community backlash over proposed licensing changes (eek!).
There are 361 spells in the PHB, but only 318 in the SRD. Which are missing?
Here are the 43 spells in the PHB but not the SRD:
arcane gate
armor of agathys
arms of hadar
aura of life
aura of purity
aura of vitality
banishing smite
beast sense
blade ward
blinding smite
chromatic orb
circle of power
cloud of daggers
compelled duel
conjure barrage
conjure volley
cordon of arrows
crown of madness
crusader’s mantle
destructive wave
dissonant whispers
elemental weapon
ensnaring strike
feign death
friends
grasping vine
hail of thorns
hex
hunger of hadar
lightning arrow
phantasmal force
power word heal
prayer of healing
ray of sickness
searing smite
staggering smite
swift quiver
telepathy
thorn whip
thunderous smite
tsunami
witch bolt
wrathful smite
Why are they missing? Well, the official WoTC answer is:
In general, the criteria for what went into the SRD is if it (1) was in the 3E SRD, (2) has an equivalent in 5th edition D&D, and (3) is vital to how a class, magic item, or monster works. For example, the 3E SRD has the delay poison spell, but in 5th edition that’s handled by the protection from poison spell, so protection from poison is in the SRD.
Wizards of the Coast, SRD5.1 FAQ
Looking at the actual list, every single spell missing was (1) not in the 3E SRD, (2) was added in 5E. I was curious what fraction of new 5E spells got added to the SRD vs. not, but it looks like no one has a list of new 5E spells, so I couldn’t easily check.
The following are renamed but present in the SRD, presumably for trademark reasons:
drawmij’s instant summons, evard’s black tentacles, leomund’s secret chest, melf’s acid arrow, mordenkainen’s faithful hound, mordenkainen’s magnificent mansion, mordenkainen’s private sanctum, otiluke’s freezing sphere, otiluke’s resilient sphere, otto’s irresistible dance, rary’s telepathic bond, tasha’s hideous laughter, and tenser’s floating disk are all shortened. They become instant summons, black tentacles, secret chest, acid arrow, faithful hound, magnificent mansion, private sanctum, freezing sphere, resilient sphere, irresistable dance, telepathic bond, and floating disk.
bigby’s hand becomes arcane hand
mordenkainen’s sword becomes arcane sword
nystul’s magic aura becomes arcanist’s magic aura
Pakistan has blocked access to Wikipedia. Old Wikipedia is now available in urdu, and has the same content.
We are working on more clearly communicating the Old Wikipedia is not Wikipedia in Urdu like we do in English–translation help would be welcome!